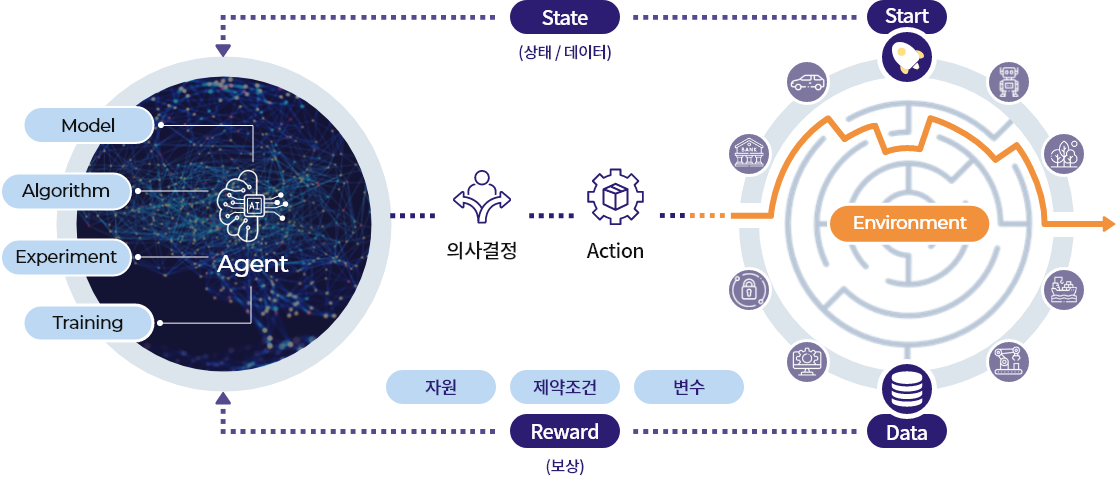

Transforming Real to Virtual World
문제해결을 위한 현실의 환경을 AI모델이 학습 가능한 가상의 환경으로 손쉽게 전환하는 방법을 제시합니다.
오프라인 강화학습용 '정적데이터'를 학습하기 위한 환경과, 디지털 트윈 기반의 시뮬레이터 환경 연동을 통한 '동적 데이터' 환경 모두를 지원합니다
-
Real
해결이 필요한 문제와
제약조건들 - 사람 아이콘 화살표 아이콘 Digital Twin
-
Virtual
AI 모델과 학습을 위한 환경의 구성
혹은 Simulator 연계
User-selected Reward system
사용자가 원하는 방식으로 의사결정시스템에서의 보상을 설정할 수 있도록,
선택 가능한 3가지 보상시스템을 제공합니다.
-
Auto Reward (Wizard)
Auto Reward (Wizard)
주어진 요소만으로 기능 실행 시,
BakingSoDA Engine이 알맞은
보상을 자동으로 제안 -
Semi-Auto Reward
Semi-Auto Reward
사용자가 손쉽게 보상을 정하도록
기본적인 설정만 제공하는 방식 -
Custom Reward
Custom Reward
고객이 원하는 방식으로
보상 값을 직접 설정
(Code Level 지원)
Hyper-parameter Auto tuning
모델학습 시 AutoML 기반의 파라미터 튜닝 설정기능을 통해
성능 향상과 동시에 작업 시간을 단축시키고 사용자 편의까지 고려합니다.
- Parameter
- Basic
- Train Parameters
- Agorithm Parameters
- Model Parameters
-
Performance Enhancement
Performance
Enhancement -
Save Time
Save Time
-
User Convenience
User Convenience
UI-based Usability
강화학습을 학습한 개발자나 분석가로 한정되어 있던 주 사용자층을 확대하여
별도의 학습 없이도 직관적으로 실행 가능한 UI 를 제공합니다.
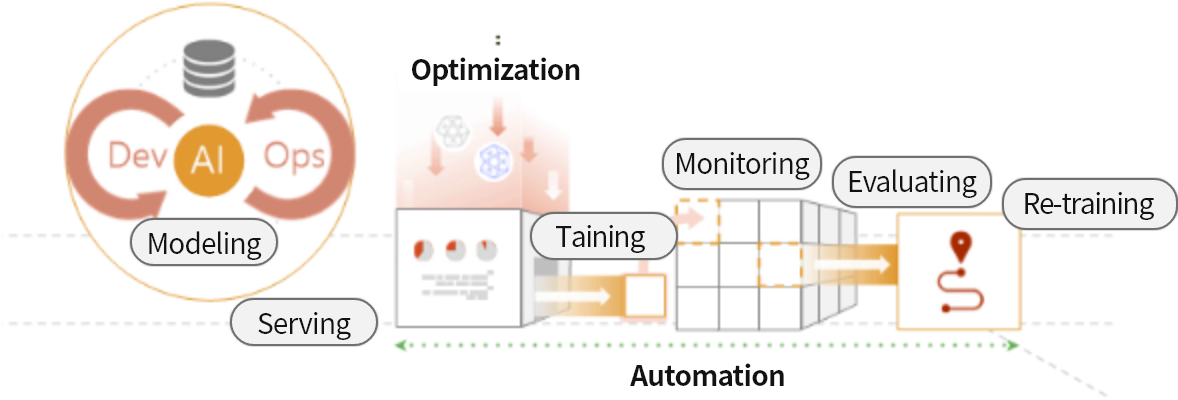
MLOps-based Learning & Operation system
최적의 결과를 위한 의사결정시스템을 최적의 성능으로 유지하기 위해
모델생성에서 전달 / 성능 모니터링 / 평가 / 재학습에 이르는 전체적인 학습모델 관리 기능을 제공합니다.